
Our biggest downtime yet
Hello, I am MrLeRien. I manage Soleil Levant.
At about 4:30 AM EST+2, the VM holding almost every crucial service on Project Segfault got abruptly shut down by QEMU, as it detected that the disk has gotten full.
In this blog post, I'm gonna tell you how it happened, why it happened, how come we didn't act on it earlier and how we're going to overhaul Soleil Levant as a whole to get a better grasp of our service as it comes down.
How?
As I've said, QEMU abruptly shut down due to a full disk drive but it isn't the full story. I've moved the .qcow2 file from the root partition to the raid partition, resized it to +1TB in qemu-img, went to gparted and this is what I saw:
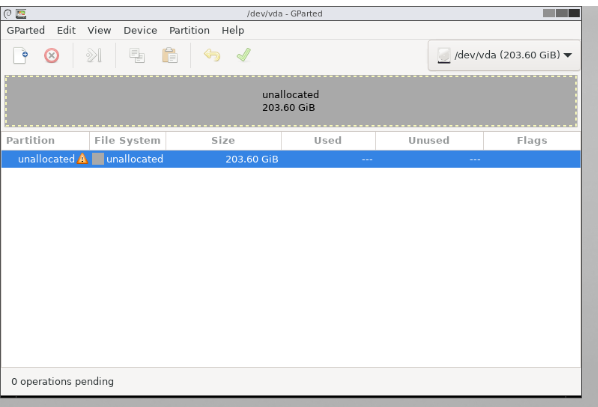
I don't know how qemu-img screwed it up. I've done this a dozen times even before Project Segfault was a thing, yet it went through and corrupted the disk.
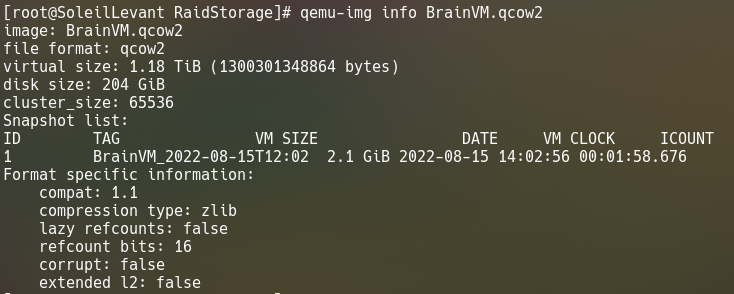
Either Debian/ext4 corrupted itself, or it was qemu-img. And that is where I discovered something very lucky.
This isn't the first time Brain has a storage problem. When we formatted the raid partition, I moved the qcow image from Raid to root. And as it took too much time to copy the rest of the VMs, I started BrainVM there since I didn't want more un-necessary downtimes.
We almost ran out of space in fact while we were doing the Raid FS transition. I still had 60 or so GB left on root, so I just resized it to +60GB, repartitioned in gparted and called it a day. This is where the snapshot comes from. it was after resizing the image but not the partition yet. Dated August 15th.
This was our only hope to save BrainVM. I reverted to it, took about 20 or so minutes, but it worked and the next thing I saw was gparted, still unpartitioned from the 60 gigs I gave 12 days ago. Moved it to Raid, made sure to have a fucking disk backup, resized it to +512G in qemu-img and gparted, and booted. This is where we are today.
Why is everything under a single VM?
This VM comes back to when we used Windows Server for the hypervisor. We didn't have much services back then, but next thing we know we added more people and added more stuff to the same VM.
Why didn't you have more backups?
This is honestly my fault for not taking enough measures to backup BrainVM, and I'm sorry about that. A backup solution was in the pipeline, as we also thought at the time that having everything under a single VM's shoulders was a bad idea, but didn't commit to it soon enough.
I plan to make more backups though, as starting today, the VM will get daily snapshots until we overhaul Soleil Levant's management to not have everything under one VM.
Off-site backups are also being planned, for a while now actually, but the person who is going to manage the off-site backups has work and stuff, which most of us don't.
This is all I have for you today, don't be stupid and backup your stuff folks.