
About Soleil Levant's downtime
On the 27th of August 2023, around 8:30 PM UTC, Soleil Levant, our main server hosted in France, had heating issues.
MrLeRien tried keeping part of the case open for better airflow but that didn't seem to help.
In around another hour or two, we discovered that one of the HDD lights went yellow.

What we did?
Once we realized the issue, the server was almost immediately shut down. However, there was still some data being written into during this time, which resulted in some data being corrupted (I'll expand on this later in the article).
This all happened when most of the sysadmins were offline (gotta love timezones eh?).
MrLeRien got 2 drives to replace these on eBay, but they were estimated to take almost a week to arrive. This was also a thursday night, making matters even worse.
However, we had one "beacon of hope", that was a hot swap HDD from someone MrLeRien knew. This however couldn't be confirmed, since all this was unfolding during midnight..
In the morning, we got the information that he had agreed to give us a drive when he comes back home.
This however, would take a while (everything unfolded around midnight, while the drives only reached around 7 PM)
As soon as we got the drives and booted into MegaRAID (yes, we unfortunately use hardware RAID5), only to notice that another drive started clicking. Thankfully, by the time the RAID was rebuilt, the clicking stopped.
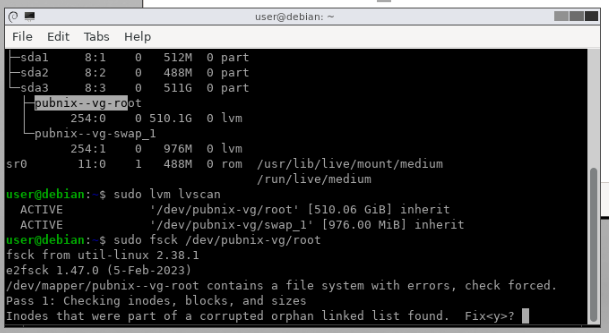
However, by the time we booted into Proxmox VE, we found out that some VMs asked for a manual fsck, namely DatabaseVM and PubnixVM. The PubnixVM had to be manually booted into gparted and fsck'd (and seemed to have worked after that without issues), while DB just booted in after it complained.
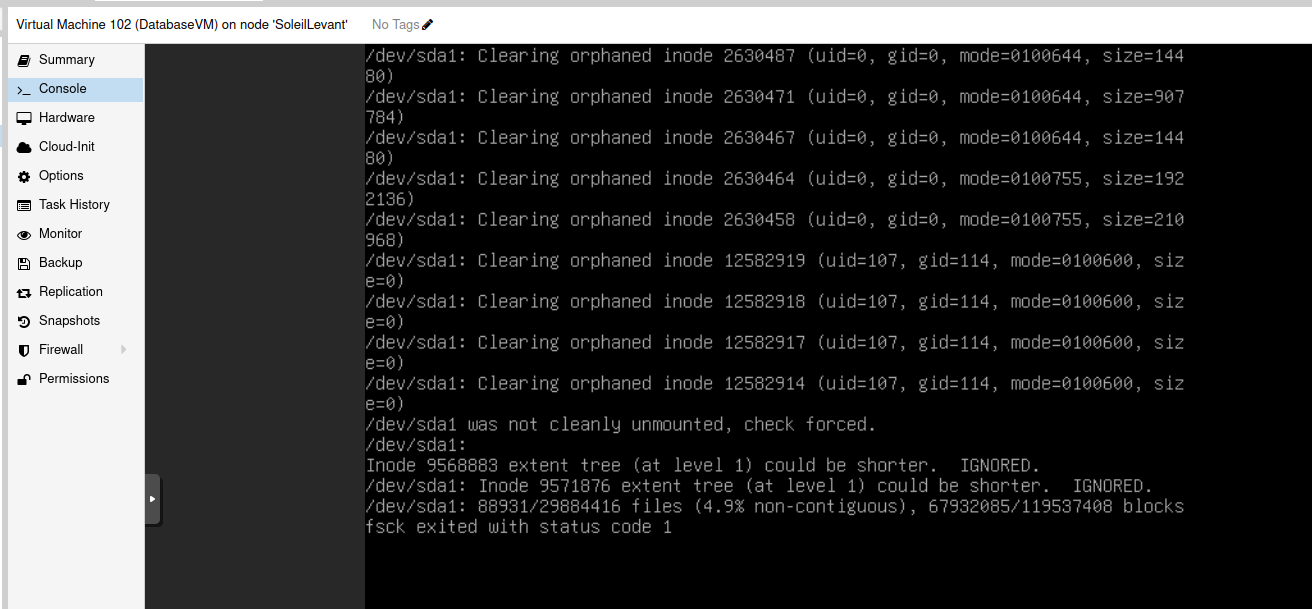
After all this was done, most of our services started coming back up. The biggest exception to this was our Matrix instance, which though booted had consistent federation issues.
By this time, it was pretty late in India so Arya went offline. This time was mostly spent trying to make sure the other services were stable and figuring out borgmatic.
It was during this time we realized that there was data corruption in a few databases. This also prevented backups from taking place since pg_dumpall failed when it tried to back up corrupted rows.
After a few pg_dump's on each of the DBs by Arya on the next day, we got the final result. A lot of Matrix Synapse stuff, and non-important stuff in Kbin and Invidious databases had corruption.
It was during this time we were reminded again that DatabaseVM backups were 4 days old.
About the DatabaseVM off-site backups
You may be asking why there hasnt been a newer backup of the DB, and there is a really dumb answer to it :(
Basically, around the time I was migrating US node to Racknerd last weekend, I also changed the backup retention as planned (and stated in the previous State of Project Segfault blogpost).
When doing this I realized that the borgmatic backups have been failing ever since the debian 12 upgrade. The next day, after all the other stuff was done, after I realized the old backups had some issues, I reset the backups and started afresh. The first backup went fine so I just left it as such.
However, the next day the healthchecks notified that the cron had failed. When I investigated, it seems like it was because when pg_dumpall was dumping, this took too long and ssh connection to rsync.net (thats what borg uses to backup) had died.
I asked midou to make a support request about it, but by the time they responded, it was too late..
I know I shouldn't have been that complacent with backups but I cant do anything about it now..
-Arya
Synapse federation broke?
After assessing the damage, Arya started investigating synapse. There wasn't any real clues in the beginning, and Arya was thinking about reverting to the previous backup once another sysadmin is online (either Devrand or Midou).
However, later, when Arya was checking some of the matrix rooms he was in, he noticed someone who ran a federation test against projectsegfau.lt (using the version-checker maubot).
This gave a server not found error, which basically meant the server couldn't be reached.
After a bit more investigation, Arya figured out this was because it was going to the Pizza1 VPS, where website traffic was redirected to while Soleil Levant was down.
Since the well-known delegation wasn't setup on the server, matrix tried to make a request to projectsegfau.lt:8448 which obviously failed.
After changing the DNS to point back to Soleil Levant, and after a restart of the Synapse server, the matrix instance started backfilling!
Originally Synapse crashed a few times due to the corrupted rows, but after restoring the database properly it happily ran fine afterwards.
Why RAID5 instead of RAID6?
This just comes down to legacy. When we first got the server (during the time of Mutahar.rocks), we initially provisioned it to be RAID5. And well, as time goes on and server was used more and more, there was no time to move to something more resilient.
Same goes for Hardware RAID. We had one opportunity to move to ZFS, after the failed Zen migration, but ZFS had been one of the primary sources of issues on Zen and we did not want to repeat it again, so we just stuck to hardware RAID.
What next?
Currently, everything is back up and we lost a week of data when it comes to matrix (which isn't this big considering it was mostly restored through federation.). The other databases were fixed and happily ran with no corruption afterwards.
We will properly add more fundings to backups when we get the possibility to do so.
Now that the 2 drives have arrived, we will have them as hotswaps for when another disk goes yellow.
This was an unfortunate incident that caused us to stay down for a week and have lost some data. We will try our best to not do this mistake again.